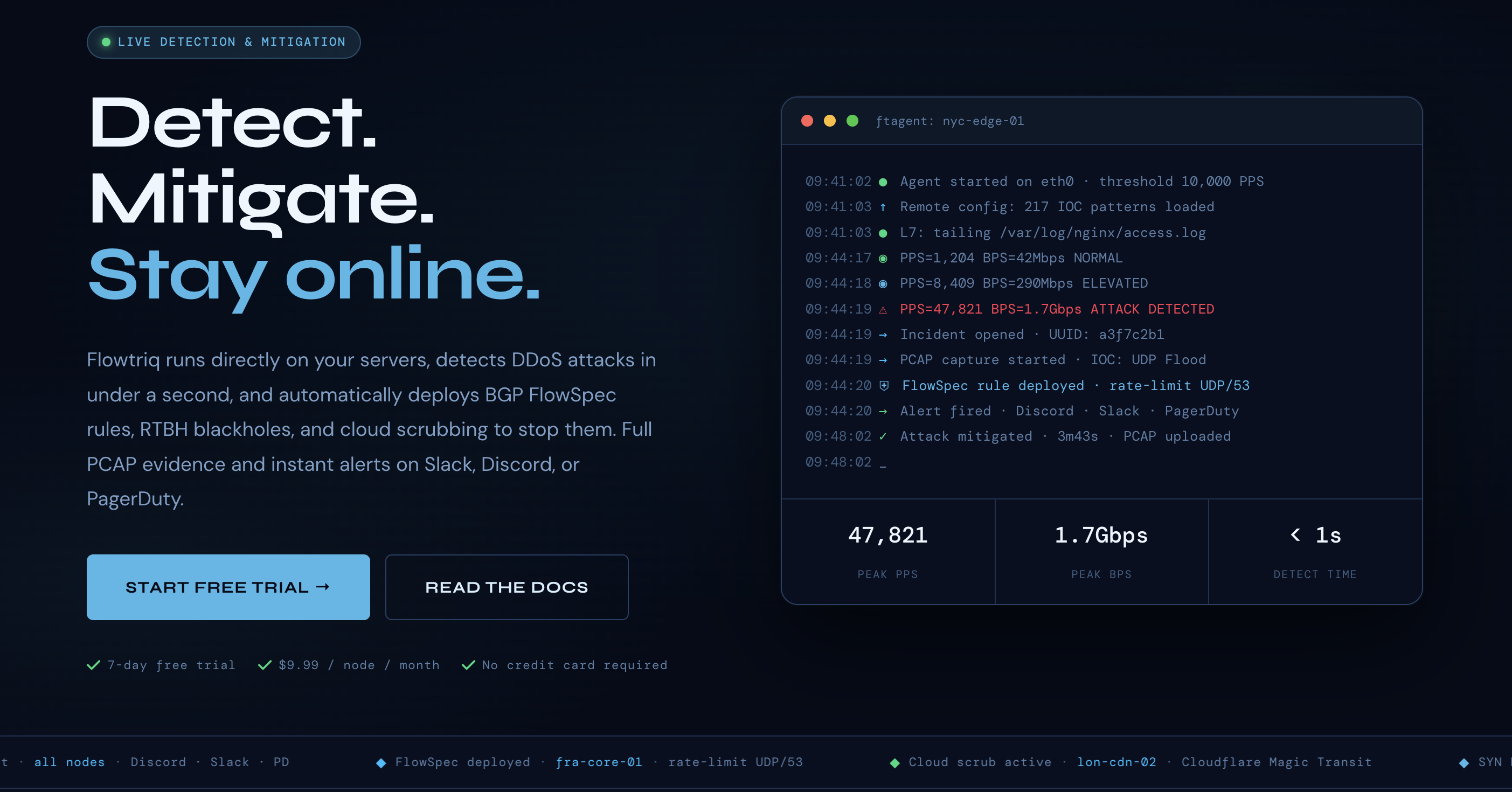
Flowtriq: Sub-Second DDoS Mitigation for Latency-Sensitive AI Infrastructure
DDoS-induced downtime erodes AI trust faster than model drift
Flowtriq is a real-time, agent-based DDoS detection and auto-mitigation platform that installs on Linux in minutes and reacts in under one second. For AI leaders running latency-sensitive inference, multi-tenant APIs, or GPU-backed microservices, that speed is the difference between a blip and a breach of SLOs. Bottom line: Flowtriq buys you availability at the edge where your models actually serve users—before your customers (or your board) notice.
The Business Case
In my 15 years building and defending AI platforms, I’ve seen more reputations lost to availability failures than to model accuracy. DDoS isn’t a rare “security” event anymore; it’s a competitive tactic against high-visibility AI endpoints and gaming/real-time apps. Flowtriq’s sub-second detection and automated mitigations (BGP FlowSpec, RTBH, or cloud scrubbing) translate directly into SLO protection: at 99.9% vs. 99.99% uptime, the monthly gap is 39 minutes—often enough to trigger SLA credits, churn, and compliance scrutiny.
The ROI math is straightforward. At $9.99/node/month with no traffic surcharges, the platform undercuts legacy scrubbing services that bill per Mbps, per packet, or per alert. One avoided 10-minute outage on a $10M ARR API can prevent $15–30k in SLA credits and lost conversions—not counting on-call fatigue or incident postmortems. Flowtriq’s automatic PCAP capture and immutable audit trails also compress incident response time, reducing mean time to mitigate and mean time to learn—two leading indicators for resilience in AI delivery.
Key Strategic Benefits
-
Operational Efficiency: Flowtriq learns dynamic baselines per host and executes prebuilt runbooks the second anomalous PPS spikes appear. Auto-captured PCAPs and centralized dashboards cut triage cycles from hours to minutes across SRE, NetOps, and SecOps.
-
Cost Impact: Flat per-node pricing removes the unpredictable egress and traffic-based fees common with pure cloud scrubbing. Expect fewer SLA payouts, reduced overprovisioning buffers, and less on-call time chasing false positives.
-
Scalability: Multi-node management supports heterogeneous fleets—GPU inference nodes, game servers, and edge POPs—while escalation policies integrate with Cloudflare Magic Transit, OVH VAC, or Hetzner for volumetric spillover. As traffic grows, your policy graph—not your headcount—scales.
-
Risk Factors: Agent-based approaches require sound change control and kernel/NIC compatibility testing on production Linux images. False positives during baseline learning or major release traffic shifts can throttle legitimate traffic unless playbooks are tuned; governance and staged rollouts are non-negotiable.
Implementation Considerations
Treat this like a reliability feature, not a security add-on. Start with a 7-day trial on canary nodes closest to revenue (inference gateways, API frontends). The ftagent installs in under two minutes; plan a 1–3 day period for baseline learning under typical load. Define escalation policies by blast radius: host-level rate limits, BGP FlowSpec to upstream routers, RTBH for sacrificial prefixes, then cloud scrubbing where applicable. Integrate alerts with Slack, PagerDuty, or OpsGenie so signal fires within one second.
Resource-wise, you’ll need a small joint tiger team: NetOps (BGP/FlowSpec), SRE (runbooks, SLOs), SecOps (IOC libraries, attack profiles), and a platform owner to drive change management. For regulated workloads, align PCAP retention with data policies; Flowtriq’s enterprise plan supports up to 365-day PCAP retention and custom IOC libraries. Expect a 1–2 week pilot, followed by a staged 3–6 week rollout across critical clusters, then long-tail nodes.
Competitive Landscape
Most enterprises default to network-edge scrubbing or cloud WAF stacks. Flowtriq’s edge is sub-second, on-host detection with automated playbooks and flat pricing—useful when you need to act before traffic even hits your upstream. Compare this to:
- Cloudflare Magic Transit (network-level scrubbing at the edge): https://www.cloudflare.com/magic-transit/
- AWS Shield Advanced (managed protection in AWS): https://aws.amazon.com/shield/
- Akamai Prolexic (carrier-grade scrubbing): https://www.akamai.com/products/prolexic
- Radware DefensePro (appliance-based, behavioral): https://www.radware.com/products/defensepro/
- NETSCOUT Arbor (TMS/APS for large carriers): https://www.netscout.com/solutions/arborddos
- Imperva DDoS (cloud-based mitigation): https://www.imperva.com/products/ddos-protection/ For peer perspectives and comparative analyses, see G2’s DDoS category: https://www.g2.com/categories/ddos-protection and PeerSpot reviews: https://www.peerspot.com/categories/ddos.
Flowtriq complements these by handling the first-second decisioning and automating escalation into your chosen scrubbing provider—particularly compelling for hybrid or multi-provider footprints.
Recommendation
- Authorize a 14-day phased pilot: 10–20 nodes across inference gateways and API edge.
- Define SLO-aligned playbooks: host throttle → FlowSpec → RTBH → scrubbing.
- Wire alerts to Slack/PagerDuty; enable automatic PCAP and immutable audit logging.
- Validate false-positive rates during traffic spikes (model deploys, promos) and tune baselines.
- If KPI targets are met (MTTM < 1s, no SLO breaches), contract at $7.99/node annual; extend to all revenue-critical nodes and align PCAP retention/IIOC libraries with compliance.
What others won’t tell you: in DDoS defense, tempo wins. Flowtriq’s sub-second moves preserve the initiative—exactly what AI leaders need when trust is measured in milliseconds.